Как я автоматизировал блог на Next.js с помощью OpenClaw: пошаговое руководство
09.04.2026164
Как я автоматизировал блог на Next.js с помощью OpenClaw: пошаговое руководство
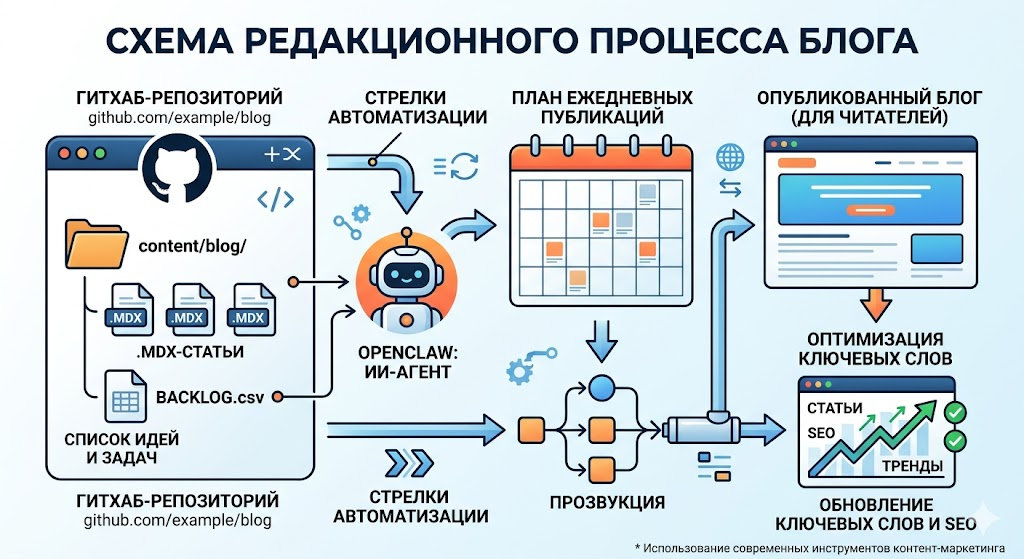
Я настроил OpenClaw так, чтобы он каждый день добавлял новый MDX-пост в мой GitHub-репозиторий с блогом на Next.js, а заодно обновлял список ключевых слов и выполнял исследование по расписанию — без необходимости самому превращаться в SEO-специалиста.
Кратко: у меня получился простой сценарий, в котором блог на Next.js хранится в виде MDX-файлов в GitHub, а агент берет на себя всю рутинную работу.
пишет и публикует статьи по расписанию
обновляет идеи по ключевым словам в течение недели
отправляет короткий отчет: заголовок, ключевые слова и ссылку на PR
Я использую OpenClaw в облаке через Clawbase, но тот же процесс подойдет и для самостоятельного хостинга OpenClaw на своей машине или на другой платформе.
Какие инструкции я дал системе
По сути, я просто попросил ассистента сделать следующее:
«Я нахожусь в Шанхае. Начиная с завтрашнего дня, каждый день должна появляться новая статья в репозитории, а в 20:00 по пекинскому времени она должна автоматически вливаться. Также каждый день в 20:00 присылай сюда короткое обновление о том, под какие ключевые слова оптимизирован материал».
Затем я добавил еще одно правило:
«Я предпочитаю заранее спланированный редакционный календарь, чтобы все было более сфокусированно. Если не появляется что-то срочное или трендовое, выбирай следующую статью из бэклога. Обновляй бэклог каждые несколько дней».
С этого все и началось — без сложных технических требований.
Что в итоге получится
Если разложить идею по шагам, получится такая система:
ежедневно публикуется одна статья в блоге
несколько раз в неделю проводится более глубокое исследование ключевых слов и анализ конкурентов
система следит за срочными и трендовыми темами, чтобы не упускать важные поводы
Что будет в GitHub-репозитории
content/blog/YYYY-MM-DD-some-slug.mdx — статьи блога
content/blog/BACKLOG.csv — редакционный календарь и бэклог по ключевым словам
Что будет в OpenClaw
Нужно настроить три задания по расписанию:
Ежедневная публикация: создание нового MDX-файла и открытие PR
Обновление бэклога: изменение BACKLOG.csv два раза в неделю
Проверка конкурентов и SERP-пробелов: раз в неделю
Начать можно только с первого задания, а остальные добавить позже.
Шаг 0. Определите формат блога
Здесь лучше выбрать самый простой и дешевый вариант:
посты хранятся в виде файлов
они коммитятся прямо в репозиторий
Vercel деплоит сайт из ветки main
Схема frontmatter
---
title: "Welcome to the Blog"
date: "2026-03-04"
excerpt: "Your blog is now powered by Markdown and MDX."
published: true
cluster: "Integrations"
---
Поле cluster необязательно, но оно удобно, если позже вы захотите фильтровать статьи по типу: настройка, интеграции, сценарии использования и так далее.
Slug в этом варианте — это просто имя файла, и это максимально удобно.
Шаг 1. Создайте папку в репозитории
В репозитории на Next.js создайте такую структуру:
content/
blog/
Этого достаточно.
Никакая CMS не нужна. База данных тоже не нужна.
Конечно, в самом приложении Next.js должен быть код, который умеет отображать блог, но это отдельная задача. Если у вас еще нет заготовки, можно попросить OpenClaw сгенерировать ее. Если структура уже есть, то агенту достаточно просто добавлять MDX-файлы.
Шаг 2. Создайте бэклог ключевых слов
Именно этот шаг дал наибольшее улучшение.
Вместо того чтобы каждый день с нуля заниматься подбором ключевых слов, я храню в репозитории простой CSV-файл.
OpenClaw может создать его сам
В моем случае я не писал этот файл вручную. Я просто объяснил OpenClaw, что мне нужно, и он сам создал content/blog/BACKLOG.csv и закоммитил его в GitHub.
Получается два варианта:
вариант A — создать файл вручную
вариант B — поручить OpenClaw инициализацию и дальнейшее обновление по расписанию
В любом случае результат должен быть одинаковым: в репозитории появляется строгий CSV-файл по пути content/blog/BACKLOG.csv.
openclaw install,Setup,Informational,"how to install openclaw; openclaw docker",Blog post,10,todo,"High intent for new users",https://example.com
openclaw slack integration,Integrations,Informational/commercial,"connect openclaw to slack; slack ai assistant",Blog post,8,todo,"Repeat the Telegram pattern",https://example.com
Важное правило для CSV
Не вставляйте внутрь CSV секционные заголовки вроде # SETUP. Файл должен оставаться строгим CSV, чтобы автоматизация могла корректно его разбирать.
Если нужно сгруппировать темы, просто сортируйте и фильтруйте строки по столбцу cluster.
Шаг 3. Включите веб-поиск
Это необязательно, но заметно улучшает результат.
Если вы хотите, чтобы обновление бэклога и анализ конкурентов были основаны на реальных данных, а не на догадках, дайте OpenClaw доступ к поисковому провайдеру.
Автор использовал Brave Search.
включите инструмент web_search в OpenClaw
сохраните ключ API Brave в конфигурации или переменных окружения, а не в чате
Так агент сможет прикреплять URL-источники прямо в BACKLOG.csv.
С точки зрения расходов это тоже удобно: модель оплаты у Brave API зависит от использования, а для личных сценариев этого часто достаточно почти бесплатно.
Шаг 4. Подключите GitHub для публикации
Чтобы OpenClaw мог публиковать статьи, ему нужно уметь:
клонировать репозиторий
создавать ветку
коммитить один MDX-файл
отправлять изменения
открывать pull request
Используйте fine-grained GitHub token
Создайте fine-grained PAT, который будет ограничен только вашим репозиторием.
Минимальная схема настройки такая:
Откройте раздел fine-grained PAT в GitHub
Нажмите Generate new token
Укажите владельца ресурса и выберите доступ только к нужному репозиторию
Выдайте минимальные права:
Contents — Read and write
Pull requests — Read and write, если хотите создавать PR
Workflows — Read and write, если агент должен редактировать GitHub Actions
После этого сохраните токен как GITHUB_TOKEN в конфигурации или переменных окружения OpenClaw.
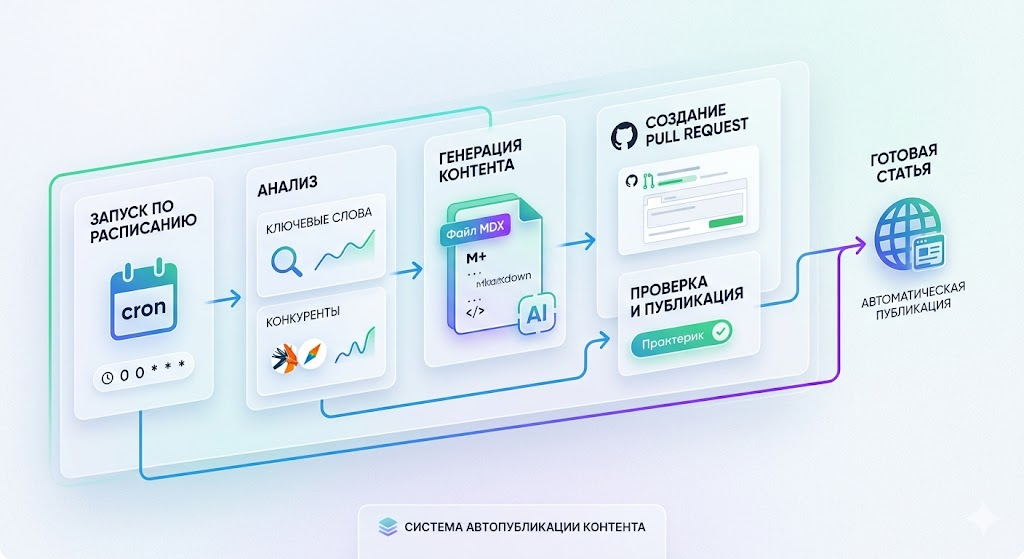
Шаг 5. Настройте ежедневную публикацию
Этот процесс полностью автоматизирован и запускается по cron.
Ежедневный цикл работает так:
читает content/blog/BACKLOG.csv
выбирает следующую строку:
с наивысшим priority
со статусом status=todo
создает новый пост в формате content/blog/YYYY-MM-DD-.mdx
открывает PR
отправляет обновление в момент публикации
Правила для контента
использовать простые слова
писать пошагово
добавлять хотя бы одну таблицу
вставлять фрагменты кода там, где это уместно
добавлять 3–6 ссылок на источники в виде обычных URL
Как выглядит ежедневное сообщение
В 20:00 по пекинскому времени автор хотел получать обновление со следующими данными:
заголовок
slug или имя файла
кластер
основное ключевое слово и вторичные ключевые слова
ссылка на PR
Шаг 6. Автоматическое обновление ключевых слов и анализ конкурентов
Эта часть тоже работает по расписанию.
Именно так удается поддерживать систему в плановом и сфокусированном режиме, а не публиковать материалы хаотично:
ежедневно — публикация из бэклога
два раза в неделю — обновление бэклога: добавить 10–20 новых качественных идей и удалить дубли
раз в неделю — проверка конкурентов и пробелов в SERP: что уже ранжируется и каких ракурсов не хватает
Благодаря этому не приходится постоянно сидеть в SEO-инструментах.
Шаг 7. Расписание SEO-агента в OpenClaw
Автор находился в Шанхае и использовал часовой пояс Asia/Shanghai.
ежедневная публикация — 20:00
обновление бэклога — 2 раза в неделю, каждые 3–4 дня
глубокий анализ конкурентов — 1 раз в неделю
Устранение проблем
Если что-то ломается, самый быстрый путь часто оказывается самым простым: вставьте точную ошибку в OpenClaw и попросите его исправить проблему прямо в репозитории.
Раз у него уже есть доступ на запись в кодовую базу, пусть он и делает рутинные исправления.
Проблема: GitHub просит логин и пароль при clone
Это значит, что среда не поддерживает интерактивную авторизацию. Используйте HTTPS URL с токеном и переменную GITHUB_TOKEN.
Проблема: BACKLOG.csv не парсится
Частые причины:
строки-комментарии вроде # SETUP
пустые строки
неэкранированные запятые
Решение:
держать файл в строгом CSV-формате
ставить запятые внутри строк только в кавычках
Проблема: OpenClaw постоянно меняет код в репозитории
Не стоит это разрешать. Лучше ограничить область работы задания:
ежедневная задача должна коммитить только новый MDX-файл
задачи обновления должны коммитить только BACKLOG.csv
Краткий вывод
Если вам нужен недорогой и автоматизированный способ публиковать контент в блог, схема выглядит так:
храните статьи как .mdx в репозитории
ведите редакционный бэклог в BACKLOG.csv
настройте ежедневное задание на публикацию следующего материала
обновляйте ключевые слова несколько раз в неделю
Для независимых разработчиков и небольших команд без отдельного SEO- или маркетинг-специалиста это удобный способ поддерживать регулярный выпуск контента без новой полной ставки в команде.
FAQ: нужен ли отдельный sub-agent OpenClaw для каждого продукта
Обычно нет.
Если вы хотите запускать один и тот же процесс для нескольких продуктов, можно оставить один экземпляр OpenClaw и разделить систему так:
отдельный файл бэклога для каждого продукта, например BACKLOG_product2.csv
отдельные cron-идентификаторы и расписания
при желании — отдельный репозиторий для каждого продукта
Обычно это самый простой вариант.
Отдельный профиль агента имеет смысл только тогда, когда нужна жесткая изоляция:
разный голос и тон для каждого продукта
разные модели и инструменты по умолчанию
разные учетные данные, репозитории или правила безопасности
отдельная память и отдельные рабочие пространства
Субагенты хорошо подходят для параллельных разовых задач, но для ежедневной публикации cron-задания обычно удобнее.
Оценка стоимости
Если один экземпляр Clawbase OpenClaw стоит фиксированную сумму в месяц и используется сразу для нескольких продуктов, то стоимость на каждый продукт снижается по мере масштабирования.
2 продукта — примерно вдвое дешевле на каждый
3 продукта — еще ниже стоимость на один проект
То есть один экземпляр можно использовать для автоматизации ежедневных публикаций сразу для нескольких продуктов и при этом удерживать разумную стоимость на проект.
Как полностью автоматизировать TikTok-аккаунт приложения с помощью OpenClaw Автоматизация TikTok-маркетинга для приложений уже перестала быть экспериментом и постепенно превращается в рабочую систему. Если раньше автору…
Как управлять сервером через Telegram с помощью ИИ: настройка OpenClaw Если вы администрируете VPS, то наверняка сталкивались с одной и той же рутиной: нужно зайти…
Как автоматизировать блог на Ghost: кейс SEO-эксперимента с 350+ постами на OpenClaw Автор темы на Ghost Forum поделился практическим кейсом автоматизации контентного блога о толковании…
09.04.2026
392
Нашли ошибку или хотите дополнить?
Помогите улучшить этот материал — предложите изменение.